
SkipFish Nedir
SkipFİsh Michal Zalewski, Niels Heinen ve Sebastian Roschke tarafından 2009 yıllında yazlılan, siteler
için otomatik zaafiyet tarama aracıdır.
Neden SkipFish

Nasıl Yüklenir
Debian işletim sistemlerinde hali hazırda geliyor farklı bir
sürümünü kullanıyorsanız Kod:
apt-get install skipfish
kodunu terminalde çalıştıralım karşımıza gelen soruları "Y" diyerek tamamlayalım
Artık Kurduğumuza göre kullanımına geçebiliriz

Kullanımı
Zafiyet taraması yapmak istediğmiz site örnek olarak Google olsun
Terminalimize yazalım
Kod:
skipfish -o /root/Desktop/tht www.google.com
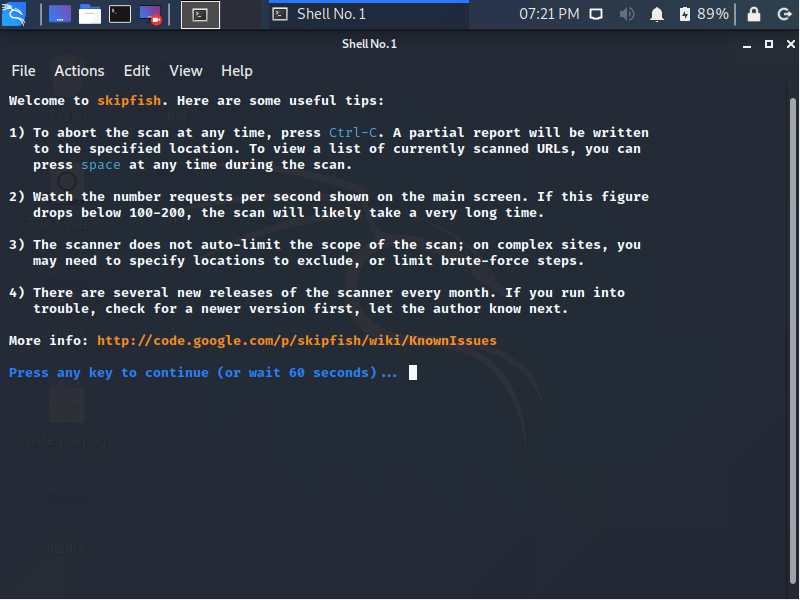
Yukarıda gördüğünüz gibi bir ekran çıktı
eğer bu ekranda beklerseniz 60 saniye sonra kendisi otomatik olarak zafiyet taramasını
başlatıyor yada herhangi bir tuşa basıp taramayı başlatabilirsin
SkipFİsh Michal Zalewski, Niels Heinen ve Sebastian Roschke tarafından 2009 yıllında yazlılan, siteler
için otomatik zaafiyet tarama aracıdır.
Neden SkipFish
YÜKSEK PERFORMANS
İnternet üzerinde saniyede 500+ istek, LAN/MAN ağlarda 2000+ , local ağlara karşı 7000+ request daha önceden yapılmış.
Çoklu ve Tekli Çekirdek Desteği Var
Gelişmiş HTTP/1.1 yüksek menzilli response ve request iletme
İçerik Sıkıştırma
keep-alive bağlantı kuralbilme özelliği
KOLAY KULLANIM
Belirsiz işlem ve sorgu tabanlı parametre işleme şemalarının sezgisel olarak tanınması
Site içeriği analizine dayalı otomatik kelime listesi oluşturma.
Olasılıklı tarama özellikleri, rastgele karmaşık sitelerin periyodik, zamana bağlı değerlendirmelerine izin verir..
İnternet üzerinde saniyede 500+ istek, LAN/MAN ağlarda 2000+ , local ağlara karşı 7000+ request daha önceden yapılmış.
Çoklu ve Tekli Çekirdek Desteği Var
Gelişmiş HTTP/1.1 yüksek menzilli response ve request iletme
İçerik Sıkıştırma
keep-alive bağlantı kuralbilme özelliği
KOLAY KULLANIM
Belirsiz işlem ve sorgu tabanlı parametre işleme şemalarının sezgisel olarak tanınması
Site içeriği analizine dayalı otomatik kelime listesi oluşturma.
Olasılıklı tarama özellikleri, rastgele karmaşık sitelerin periyodik, zamana bağlı değerlendirmelerine izin verir..
Nasıl Yüklenir
Debian işletim sistemlerinde hali hazırda geliyor farklı bir
sürümünü kullanıyorsanız Kod:
apt-get install skipfish
kodunu terminalde çalıştıralım karşımıza gelen soruları "Y" diyerek tamamlayalım
Artık Kurduğumuza göre kullanımına geçebiliriz
Kullanımı
Zafiyet taraması yapmak istediğmiz site örnek olarak Google olsun
Terminalimize yazalım
Kod:
skipfish -o /root/Desktop/tht www.google.com
Yukarıda gördüğünüz gibi bir ekran çıktı
eğer bu ekranda beklerseniz 60 saniye sonra kendisi otomatik olarak zafiyet taramasını
başlatıyor yada herhangi bir tuşa basıp taramayı başlatabilirsin
Tarama başladıktan sonra karşınıza böyle bir ekran gelicek
burada aslında çok fazla bize gereken birşey yok sadece "Issues Found" ksımındaki bulunan
zafiyetler ve dereceler gerekiyo onun dışındakiler genel bilgi
burada aslında çok fazla bize gereken birşey yok sadece "Issues Found" ksımındaki bulunan
zafiyetler ve dereceler gerekiyo onun dışındakiler genel bilgi
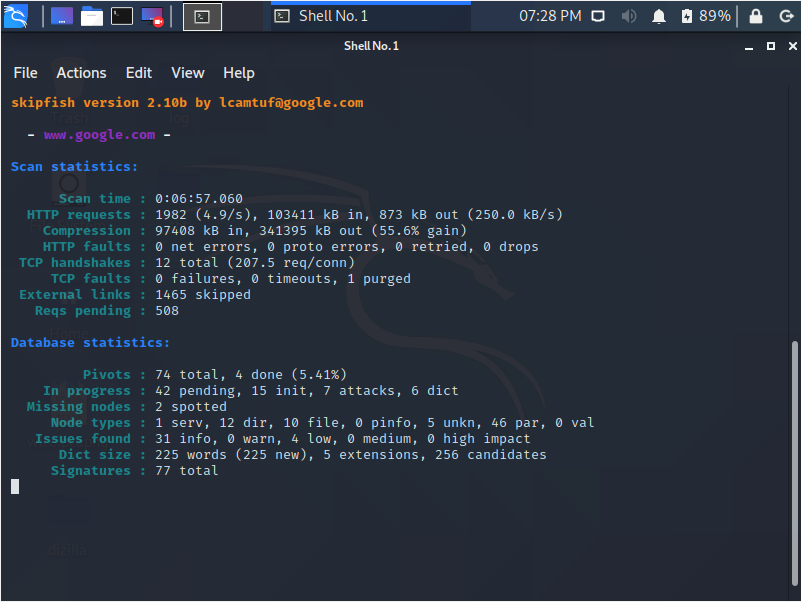
Gördüğünüz gibi yukarıda 4 adet düşük derece zafiyet bulmuş
bunların hangi zafiyetler olduğunu log tuttuğumuz dosyada bakabilirsiniz
Parametreler
-W wordlist - wordlist yolunu belirt
-o - sonuçların kayıtedlileceği doysa konumu
-A user:pass - http isteklerinde kullanıcı biligilerini belirmek için
-C name=value - bütün http isteklerine rastgele cookie atamak
-H name=value - requestlere HTTP başlığı atamak
Crawl Değeri:
-d max_depth - Maksimum crawl değerinin derinliğini belirlemek için (16)
-c max_child - İndex başına eklenecek maksimum "children" sayısı (512)
-x max_desc - "Branch" başına indekslenecek "descendant" sayısı (8192)
-r r_limit - Toplam gönderilecek request sayısı (100000000)
-p crawl% - node ve linklerin crawl ihtimali (100)
-p hex - Verilen seed ile olasılığa dayalı tarama yapma
-I string - sadece verilen string`i takip et
-X string - Verilen string`i göster
-K string - string isimli parametreleri fuzz`lama
-D domain - cross-site linklerini diğer domainlerde crawl`la
-B domain - Siteye güven ama Crawl işlemi gerçekleştirme
-O - Hiçbir formun değerini "True" yapma
-P - Yeni link bulmak için html`leri ayrıştırma
-u - İşlem sırasında ekranda bir şey gösterme
-E - Tüm eşleşmeyen HTTP/1.0 HTTP/1.1 içeriklerini log tut
-U - Gözüken bütün URL ve e-mail`leri log tut
-W wordlist - wordlist yolunu belirt
-o - sonuçların kayıtedlileceği doysa konumu
-A user:pass - http isteklerinde kullanıcı biligilerini belirmek için
-C name=value - bütün http isteklerine rastgele cookie atamak
-H name=value - requestlere HTTP başlığı atamak
Crawl Değeri:
-d max_depth - Maksimum crawl değerinin derinliğini belirlemek için (16)
-c max_child - İndex başına eklenecek maksimum "children" sayısı (512)
-x max_desc - "Branch" başına indekslenecek "descendant" sayısı (8192)
-r r_limit - Toplam gönderilecek request sayısı (100000000)
-p crawl% - node ve linklerin crawl ihtimali (100)
-p hex - Verilen seed ile olasılığa dayalı tarama yapma
-I string - sadece verilen string`i takip et
-X string - Verilen string`i göster
-K string - string isimli parametreleri fuzz`lama
-D domain - cross-site linklerini diğer domainlerde crawl`la
-B domain - Siteye güven ama Crawl işlemi gerçekleştirme
-O - Hiçbir formun değerini "True" yapma
-P - Yeni link bulmak için html`leri ayrıştırma
-u - İşlem sırasında ekranda bir şey gösterme
-E - Tüm eşleşmeyen HTTP/1.0 HTTP/1.1 içeriklerini log tut
-U - Gözüken bütün URL ve e-mail`leri log tut