

Hepinize tekrardan merhabalar THT üyeleri. Üst Seviye Python Veri Analizi serimizin son bölümü ile karşınızdayım. Önceki bölümlere gitmek için buradaki linkleri kullanabilirsiniz.
İlk Bölüm: Buradan, İkinci Bölüm: Buradan.

İlk bölümümüzde Pandas kütüphanemizin temellerini atmıştık ve ikinci bölümde ise veri analizlerine basitçe bir giriş yapmıştık. Açıkçası beklediğimin çeyreği kadar bile etkileşim almadı ne yazık ki iki konu da. Yine de son bölüm ile karşınızdayım. Bu bölümde ise Brezilyadaki Corona Virüs vakaları üzerinden tamamen veri analizini öğrenip seriyi bitireceğiz. İsterseniz konu başlıklarımızı belirteyim.
Bu Bölümdeki Konu Başlıkları:
- Daha Detaylı Veri Analizi
- Hatalı Verileri Tespit Etme, Düzeltme ve Silme
Daha Detaylı Veri Analizi
Evet, bu bölümde bir önceki bölüme oranla daha detaylı bir veri analizi gerçekleştireceğiz. Burada birkaç tane temel örnek vereceğiz ve bu yüzden tek tek hepsinin nasıl çalıştığını göstereceğim.
Hazırsak hadi başlayalım.
Kod:
import pandas as pd
dataframe=pd.read_csv("brazil_covid19.csv") #Bu komut ile veri setimizi projeye dahil ediyoruz
print(dataframe) #Bu kod ile ise veri setimizi yazdırabiliriz
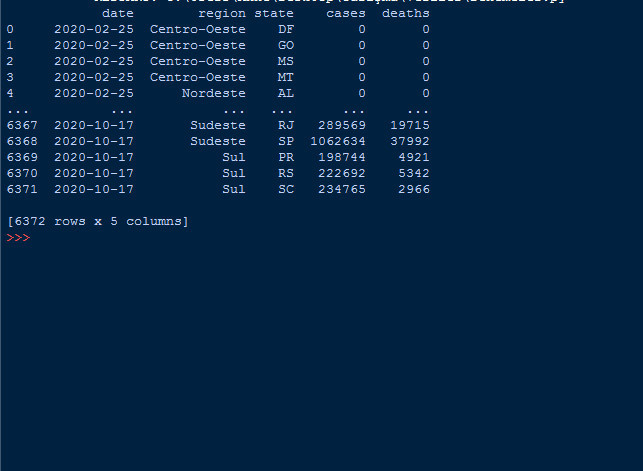
Evet, genel olarak başlangıç için önce kütüphanemizi projeye ekledik ve veri setimizi de projeye ekledik. Şimdi bu veriyi de yazdırdık.
Kod:
state=dataframe["state"] #state bölümündeki datayı sunar
print(state)
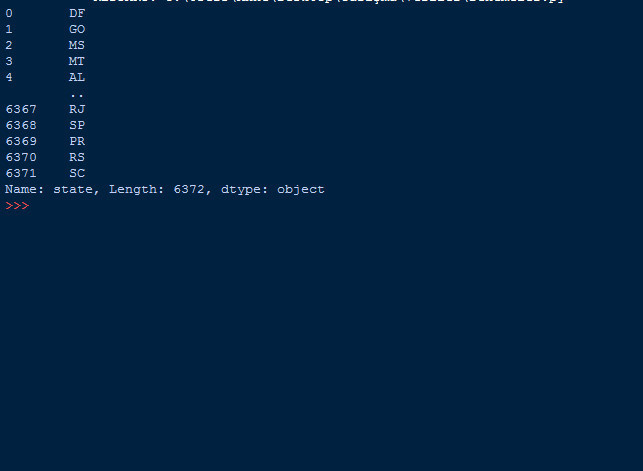
Bu komut ile ilk örnektekinin aksine tüm veri setini değil, sadece istediğimiz sütunu yazdırdık. Veri filtreleme açısından gayet kullanışlı bir komut. Çıktının en sonunda kaç satır ve kaç sütun?un yazdırıldığı verilmektedir.
Kod:
both=dataframe[["state","cases"]] #İstenilen sütunlardaki datayı sunar
print(both)
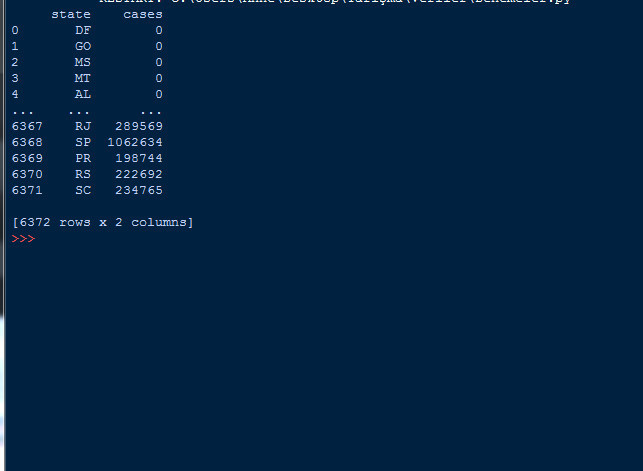
Burada ise önceki örnekteki gibi sadece tek sütundan değil, 2 farklı sütundan yararlandık. Hem şehirleri, hem de şehirlerdeki vaka sayılarını böylece görebiliriz. Tabi siz istediğiniz şekilde bu sütun sayısını arttırabilir veya değiştirebilirsiniz.
Kod:
loc=dataframe.loc[1313] #istenilen satırı yazdırır
print(loc)
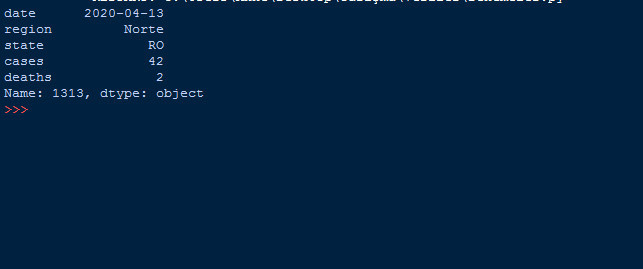
loc fonkisyonunda 2 parametre vardır: Ulaşılmak istenen satır ve ulaşılmak istenen sütun. Bu bilgileri loc fonksiyonu ile kullanırsak istediğimiz bölüme ulaşabiliriz.
Biz burada 414 numaralı satırı yazdırmak için 414 verdik değer olarak ve o da bize detaylıca çıktısını verdi.
Kod:
loc2=dataframe.loc[4141, "deaths"] #istenilen satırdaki sütun değerini yazdırır
print(loc2)
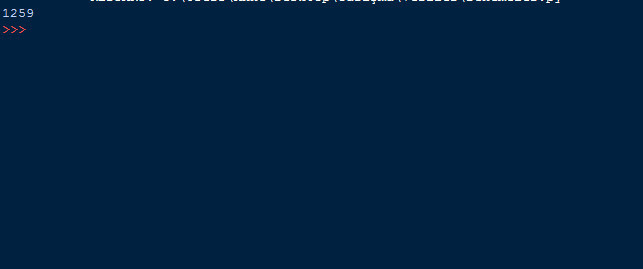
Burada ise istenilen satırın istenilen sütun verisini yazdırdık. Bu daha nokta atışlı bir aramadır.
Kod:
b=dataframe.loc[1500:1512] #istenilen aralıktaki satırlara ulaşamayı sağlar
print(b)
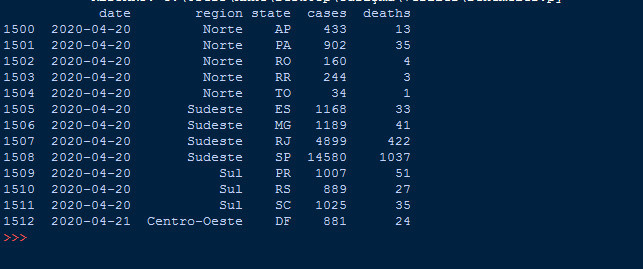
Burada ise önceki örneklerdeki gibi tek bir satıra değil, belli bir aralığına ulaştık ve detaylıca bu satırların bilgilerini aldık.
Belki fark etmişsinizdir, normalde python 1:5 olarak yazılan bir aralıkta 5 değerini almazken Pandas kütüphanesi bu değeri de alır.
Kod:
c=dataframe.loc[:,"cases"] #belli bir sütunun tüm değerlerini alır
print(c)
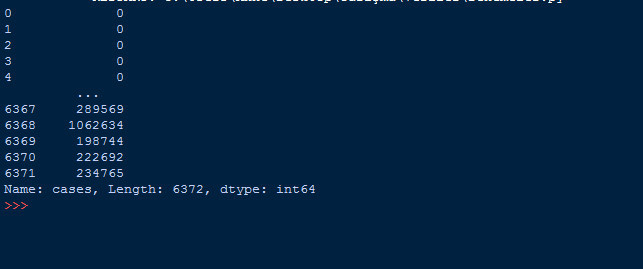
Yukarıdaki örneklerde hep belli bir satır veya satır aralığının değerlerini almıştık fakat şimdi satır kısmını boş bırakarak sütun kısmını aldık. Böylelikle bizim için tüm satırları yazdı.
Kod:
d=dataframe.loc[:,["state","cases"]] #istenilen sütunların satır değerlerini alır
print(d)

Burada ise bundan önceki örneğe ek olarak bir tane sütunun daha satır bilgilerini yazdırıyoruz.
Açıklamak gerekirse; il il corona virüs sayılarını bu kod ile gördük.
Kod:
e=dataframe.loc[2413:2420,["state","deaths"]] #istenilen aralıktaki satırların belirtilen sütun değerlerini yazdırır
print(e)

İlk önce satır aralığımızı belirttik ve sonrasında ise hangi sütunlarını okumak istiyorsak o sütunları yazdık.
Burada yaptığımız şey ise tam olarak istediğimiz satırlarda bulunan şehirdeki ölüm sayılarını gözden geçirmek oldu.
Kod:
f=dataframe.iloc[5000] #istenilen index değerine sahip olan bölümü yazdırır.
print(f)
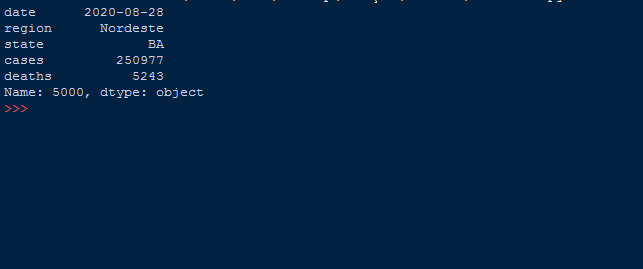
Her zaman bizim şu an üzerinde çalıştığımız veri setindeki gibi index ile satır numaramız aynı olmaz. Bu tür durumlarda iloc fonksiyonu kullanılır. Bu fonksiyon ile istediğimiz satırdan ziyade istediğimiz index değerine sahip olan bölüm yazdırılır.
Burada 5000 index değerine sahip olan kısmı yazdırdık.
<div style="margin:20px; margin-top:5px"> Kod:
<font color="palegreen">h=dataframe[dataframe.deaths